横排-无底-140x48mm-04-1.png "前沿科技阵地")
竖排-无底白字-280x96mm-04.png "前沿科技阵地")

在AMD“跑步进入7nm时代”的行动中,GPU扮演了开路先锋的角色。在今天召开的Next Horizon技术大会上,AMD就宣布了全球首款7nm制程GPU产品:主要用于人工智能、云计算和高性能计算的AMD Radeon Instinct MI60和MI50数据中心GPU。MI是Machine Intelligence的缩写,可以很清晰地反映AMD Radeon Instinct产品线的定位。

在看到竞争对手凭借专业计算卡在人工智能和高性能计算领域混得风生水起后,AMD在一年多前正式推出了Radeon Instinct系列,用以取代之前的FirePro S。而在今年,Radeon Instinct随着7nm制程的升级也进行了产品升级,从之前的MI25升级为MI60和MI50。
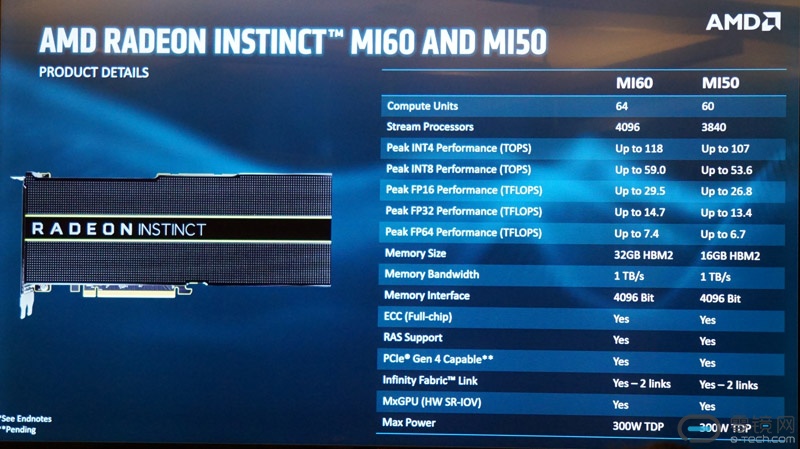
我们先来看看AMD Radeon Instinct MI60和MI50的具体指标。从现场展示的PPT来看,MI60和MI50的规格差距并不大,二者的计算单元数量分别为64个和60个,流处理器数量分别为4096个和3840个。

MI60和MI50依然是基于VEGA GPU架构,但是AMD在采用7nm制程工艺的同时,对其核心架构进行了部分优化升级。比如优化了ALU算术逻辑单元,也增加了ECC完全校验功能,采用PCIe 4.0接口标准等。

其核心规模从14nm VEGA 10的125亿晶体管增加至7nm VEGA核心的132亿晶体管,不过因为其制程工艺的提升,核心面积从484平方毫米降低到了331平方毫米。同时其核心尺寸仅相当于竞争对手的大约40%,因此MI60和MI50在部署成本和密度方面具备相当的优势。

相比之前的MI25,MI60将内存带宽提高到了夸张的1TB/s,集合32GB HBM2存储,其数据单款基本达到了顶峰。同时,其还实现了包括GPU和存储在内的全面ECC校验,以及PCIe 4.0接口。

架构的优化、制程的提升以及存储带宽的扩大,使得MI60可以提供强大的混合精度FP16、FP32和INT4/INT8能力,从而满足动态工作负载的需求,特别是从训练复杂神经网络到运行针对这些训练网络的推理。同时,MI60还是目前世界上最快的双精度PCIe 4.0加速器,提供了高达7.4TFLOPS的峰值FP64性能,能够更有效地处理包括生命科学、能源、金融、汽车、航空航天、学术、政府、国防等行业的高性能应用。

相比MI25,MI60的FP16浮点性能提高了20%,INT8、INT4整数性能分别提高了140%、380%。凭借在INT8和FP64方面的性能改进,AMD得以将其Radeon Instinct产品线的应用场景从MI25时代的神经网络训练和虚拟化,扩展到了推理计算和高性能计算领域。

另外,通过PCIe 4.0接口和Infinity Fabric Link GPU互连技术,AMD可以通过硬件桥接的方式,实现八张加速卡分成两组的彼此互联。通过桥接,MI60可以实现高达6倍的快速数据传送,每个GPU的两个Infinity Fabric链路拥有多达200GB/s的对等带宽。
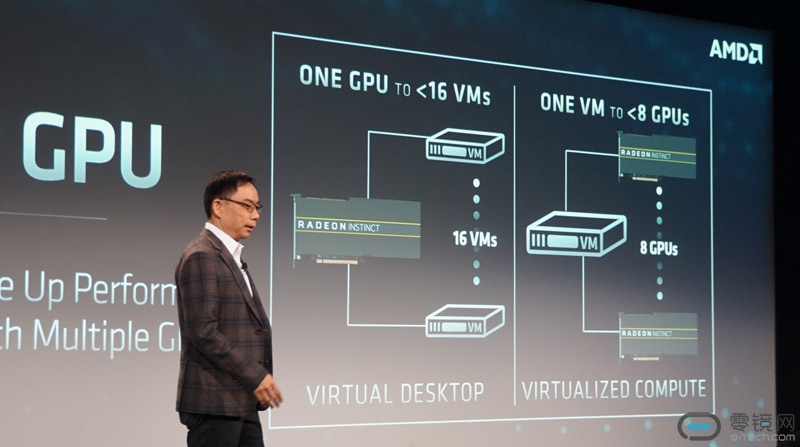
而在8张加速卡可以基于硬件虚拟化实现灵活组合,从一张加速卡支持16个虚拟机,到一台虚拟机拥有8张加速卡。

同时,其组合方式也非常灵活。1台服务器内拥有的8张加速卡可以采用灵活分组的方式,配置成为拥有1张、2张、4张以及8张加速卡的虚拟机。

在推出全新加速卡之外,AMD还宣布了用于加速计算的ROCm开放软件平台的新版本,该平台支持新加速卡的体系结构特性,包括众多开源体系下的新套件和库。它允许客户在开放环境中部署高性能、节能的异构计算系统。AMD Radeon Technologies Group高级副总裁David Wang在接受零镜网记者采访时表示:目前AMD拥有接近2000人的软件开发团队,会通过内部开发和外部协同的方式,不断支持ROCm开放软件平台的改进和升级。显然,在英特尔CUDA的成功案例在前,AMD也希望凭借更高费效比的硬件和免费开源的软件来抢回更多的市场。












