横排-无底-140x48mm-04-1.png "前沿科技阵地")
竖排-无底白字-280x96mm-04.png "前沿科技阵地")

英伟达在今年10月公布了全新的RTX 40系列显卡,而预热多时的全新Ada Lovelace架构也一并亮相。相比之前的RTX 30系列和Ampere架构,全新的RTX 40系列和Ada架构带来了自英伟达为GPU加入硬件光线追踪技术之后、图形计算发展史上最重大的一次变革。简单来说,全新的RTX 40系列和Ada架构,更深度的引入了AI计算对视觉计算的“反哺”,利用全新的DLSS 3技术,实现了游戏画面、效率和速度的全方位提升。今天本文的核心内容,就围绕这个话题而来。
顶级产品首发:RTX 40系三款产品一览
本次首发的产品一共有三个,分别是RTX 4090、RTX 4080 16GB和RTX 4080 12GB。我们先简单解读一下这三款产品的信息。

RTX 4090:AD102芯片、16384个CUDA核心,2520MHz Boost频率
首先来看RTX 4090。它采用的是AD102芯片,拥有16384个CUDA核心,Boost频率高达2520MHz,当然,这个频率实际上是官方频率,部分第三方厂商的显卡频率会更高一些。显存方面,RTX 4090配备了384bit 24GB GDDR6X显存,总带宽来到了1008GB/s。功耗方面则是维持450W的TGP值。

从基本参数来看,RTX 4090的CUDA核心数量是上代产品RTX 3090Ti的大约1.6倍,频率是上代产品的大约1.35倍,显存数据和上一代RTX 3090Ti持平,TGP也完全相同。
由于规模更大,RTX 4090在理论算力方面的数据要高出RTX 3090Ti不少:比如RTX 4090的纹理填充率是RTX 3090Ti的大约2.06倍,像素填充率是大约2.4倍,RT FTLOPS光线追踪性能是大约2.5倍,FP32性能是大约2倍等,当然除此之外,RTX 4090还有更多架构上的变化和升级,也有很多新的技术是前代产品完全不支持的,比如全新更新的DLSS 3,我们放在后文会更详细的解释。
RTX 4080 16GB:AD103芯片、9728个CUDA核心,2505MHz Boost频率
RTX 4080目前被分为2个芯片,一款是16GB显存的,使用了AD103芯片。AD103这个档次的芯片,之前都是被使用在移动平台作为顶级移动GPU使用,目前是“下放”到了RTX 4080这个产品标号上(相应的,之前GA102也被使用给“80”这个型号,不过考虑到RTX 30系的工艺非常保守,晶体管数量较少,这也是可以理解的)。

RTX 4080 16GB拥有9728个CUDA核心、Boost频率也来到了2505MHz。显存位宽为256bit,配备16GB GDDR6X显存,带宽为716.8GB/s。TGP功耗则只有320W,比RTX 4090低了不少。
基本参数来看的话,RTX 4080 16GB的CUDA核心数量是上代产品RTX 3080Ti的大约0.9倍,频率是上代产品的大约1.5倍,显存位宽方面RTX 4080 16GB是低于上代RTX 3080Ti的,毕竟后者采用的是GA102大核心,拥有384bit显存位宽。显存带宽方面,RTX 4080 16GB也比RTX 3080Ti低了不少,大约是后者的78%。由于芯片相对规模更低,RTX 4080 16GB的TGP功耗也只有320W,比上代低大约不到10%。
虽然整体规模看起来,RTX 4080 16GB比RTX 3080Ti要小了一些,但是实际上,RTX 4080 16GB在某些情况下性能是可以超越RTX 3090Ti的,整体性能在几乎所有场合下都完胜RTX 3080Ti。因为从晶体管数量来看,RTX 4080 16GB的AD103集成了459亿个晶体管,RTX 3080Ti的GA102只有283亿。对半导体产品来说,晶体管数量和最终呈现的性能、功能是基本成正比的,所以,虽然规模略小,但是完全不需要怀疑RTX 4080 16GB的性能。
RTX 4080 12GB:AD104芯片、7680个CUDA核心,2601MHz Boost频率
本次发布会上,定位最低的一款产品是RTX 4080 12GB,采用的是“正常”情况下的“80”系芯片AD104,产品被称为RTX 4080 12GB,包含了7680个CUDA核心,Boost频率为2601MHz。显存位宽被进一步降低到192bit,采用12GB GDDR6X显存,带宽为504GB/s。TGP功耗缩减至只有285W。

按照惯例来说,英伟达应该选用RTX 3080来对位比较RTX 4080 12GB,毕竟两者都是“104”系芯片,但实际上,考虑到全新的Ada架构的强悍实力,英伟达还是选择了GA102核心的RTX 3080 12GB来比拼RTX 4080 12GB。RTX 4080 12GB的CUDA核心只有RTX 3080 12GB的85%,频率是后者的1.52倍。显存位宽方面,RTX 4080 12GB只有192bit,是对比显卡的一半,显存带宽504GB/s,是对比显卡的大约60%。功耗方面,RTX 4080 12GB的TGP功耗为285W,比RTX 3080 12GB的350W低了不少。
同样,RTX 4080 12GB的参数看起来比RTX 3080 12GB差了不少,但是RTX 4080 12GB的AD104晶体管数量为358亿,比后者的283亿也要高了不少。考虑到架构的改进和频率的提升,RTX 4080 12GB性能相比后者,也是轻松胜出的。
让光和AI成为最伟大的画师:Ada架构特性简介
在基本了解了三款新显卡的产品信息后,我们来进入一个新的部分。在这个部分,本文将针对Ada架构的内容进行介绍和解读。由于这部分内容比较枯燥和难懂,我们在解读方面将尽可能多采用各种比喻、类比来降低阅读难度。如果不愿意阅读这部分内容的读者,也可以直接跳到后文的性能测试部分。
工艺和架构规模:TSMC 4N工艺立功,AD102规模相比上代暴增
对半导体和芯片产业而言,推动这个行业发展的主要力量就是制造工艺的进步。谁能更早、更快的在单位面积上容纳更多的晶体管,谁的最终产品也就是芯片就有更大可能具有更为卓越的性能。不过,工艺的选用往往会和市场情况相结合,厂商也会综合考虑市场、价格和竞争等多方面因素。
在之前的也就是2020年发布的RTX 30系显卡上,英伟达选用的是三星的8nm工艺,这实际上是三星10nm工艺的改进版本,三星早在2017年就公布了这个工艺的情况。从GPU行业发展的角度来看,英伟达在2020年选择三星2017年的工艺,应该是从市场和利润、技术应用角度充分权衡后的结果,毕竟2020年GPU市场上英伟达没有竞争对手,选择便宜的老旧工艺提高利润率是理所应当,好在2020年的三星8nm工艺相比2018年英伟达在Turing架构上选择的TSMC 12nm工艺还是有所提升的——12nm工艺其实也是更老的Pascal架构的14nm工艺的小改版本。换句话来说,英伟达在失去实际意义上的竞争对手后,工艺方面开始更倾向于成本和利润。(是不是类似于Skylake架构发布后的英特尔?)

在新的RTX 40系列显卡上,英伟达改用了全新的TSMC N4工艺。这是TSMC 5N工艺也就是5nm工艺针对英伟达的改进版本,在一定程度上也可以理解为4nm工艺(当然严格意义来说,不存在4nm工艺这个节点)。相比之前的三星8nm工艺每平方毫米大约4500万个晶体管,TSMC N4工艺的密度来到了大约每平方毫米1.25亿晶体管,暴涨了约3倍。
更高的晶体管密度,使得英伟达可以更为从容的在GPU内部布置更多的单元和实现更多的功能,因此我们也看到了这次强悍的AD102 GPU。
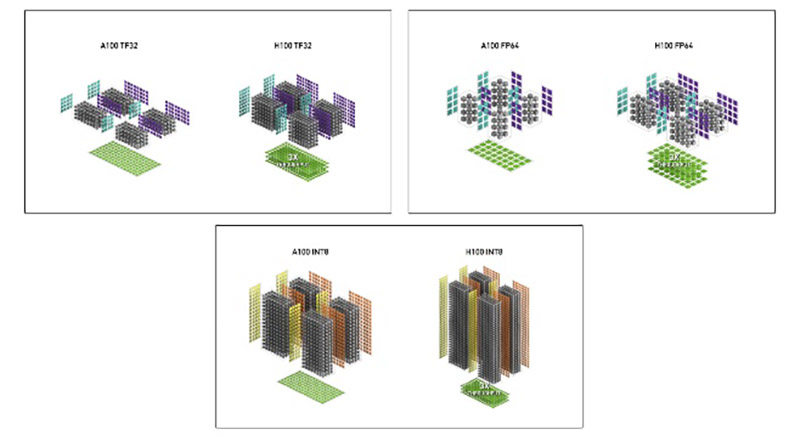
完整版本的AD102 GPU规模相当巨大。AD102内部拥有12个GPC,72个TPC、144个SM、12个32bit GDDR6X内存控制器,以及144个RT核心、576个张量核心、576个纹理单元、288个FP64核心——还有最重要的18432个CUDA核心。如果你对上述所有内容表示迷茫的话,那没有关系,AD102的规模,仅从CUDA核心数量来看的话,大约是上代顶级产品GA102大约1.7~1.8倍之多,更为巨大了。
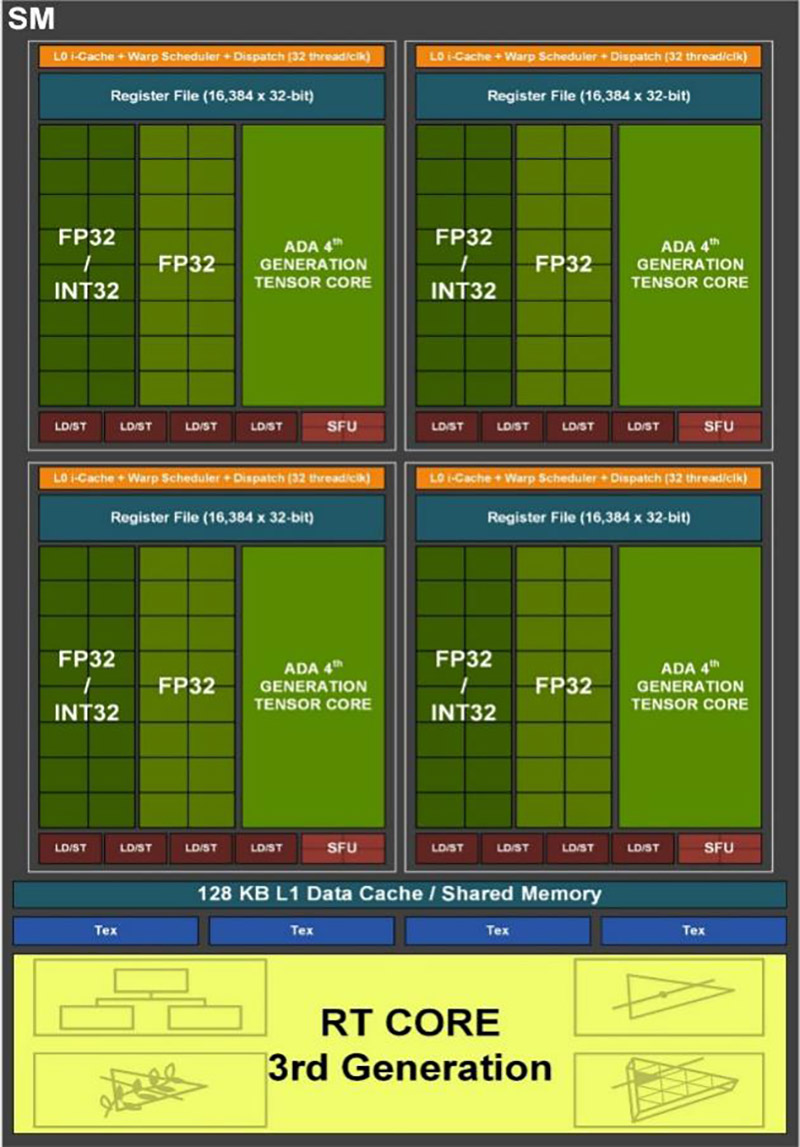
当然,如果仅仅是规模翻倍的话,实际上AD102只需要现在大约2/3的规模就够了。更多的1/3规模,用到了增加至上代16倍的、高达96MB的L2缓存,以及全新的第三代光线追踪单元、全新的第四代张量核心之上了。这些内容才是本次Ada架构更新的重点。
在这里,我们简单提及一下有关Ada架构L2缓存暴增16倍的内容,这对任何“传承有序”的半导体厂商而言,暴增某一部分,要么是架构方面有特别的发现,要么是有无法解决的问题必须大规模堆硬件。Ada架构看起来更像是前者的原因。英伟达的解释则是,增加的L2缓存将使得GPU所有部分都有巨大收益,尤其是光线追踪、路径追踪等复杂操作。
简单来看的话,Ada架构暴增的L2缓存,可能和现代GPU设计中,带宽瓶颈、计算需求以及工艺红利等多方面因素相关,与此类似的是AMD就在GPU中增加了最高达128MB的“无限缓存”。Ada架构增大L2缓存后,大量计算中间内存可以直接存放在96MB缓存中,而不是像上代Ampere架构那样6MB L2缓存不够用后需要存放至本地显存,这样既增大了存储带宽压力,还带来了较低的数据命中率和较高的延迟。
就像英伟达提到的那样,巨大的L2缓存为GPU全局都带来了显著的性能提升,尤其是AD102相比GA102规模暴增1.7~1.8倍的情况下,显存带宽依旧维持约1TB/s而不成为瓶颈,96MB的L2缓存应该起到了巨大作用。英伟达在这里肯定做了多方对比,比如提升显存控制器至512bit来对比更大的L2缓存。要知道,512bit的显存控制器带来的不仅仅是晶体管数量增加,还有功耗和显存成本上升,相比之下,更大的L2缓存在GPU性能最终的综合表现方面应该会更为出色,最终成功中选。
更快地操作光的艺术:全新的第三代光线追踪单元
Ada架构的另一个核心特点就是全新的第三代光线追踪单元,也就是RT单元。这个新的单元引入了三个重要的特性,分别是用于处理半透明材质的Opacity Micromap,以及用于复杂几何模型的Displaced Micro-Mesh Engine,还要用于提高执行效能的Shader Execution Reordering。我们一个个来解释他们的用途。

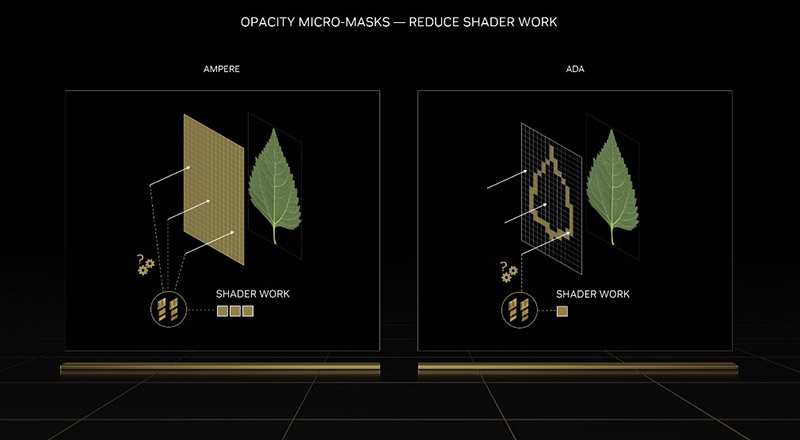
首先是Opacity Micromap,直译为不透明微图单元。这个新的功能部件的作用主要是大幅度提高了光线追踪计算过程中针对半透明物体的效率。在没有不透明微图单元的时候,光线追踪遇到半透明或者透明物体,比如树叶边缘或者火焰、或者类似其他的东西,光线判断的过程需要启用SM进行计算,SM对这种计算效率不高,需要一次次循环计算判断,占用SM大量计算时间还拖累了SM应该执行的其他计算。在不透明微图单元出现后,通过新增的不透明微图蒙板判断,不透明微图单元可以直接确定绝大部分的不透明或者透明三角形,只把最后难以判断的一小部分交给SM判定。换句话来说,不透明微图单元这种专用单元,大大提高了这个过程的计算效率。英伟达的数据是类似的计算性能提高了100%,效果非常出色了。
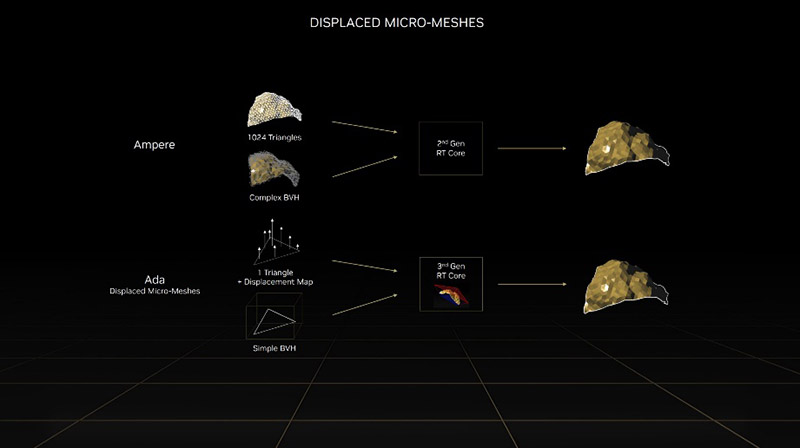
其次是Displaced Micro-Mesh Engine,直译为置换微网络引擎,简称为DMME,这个引擎执行的操作就是Displaced Micro-Mes,置换微网络,简称为DMM。DMME的作用就是在面对那些几何形态特别复杂的单元时,比如英伟达举例的螃蟹、雕塑体或者其他拥有几万甚至几十万三角形的物体,之前的计算需要一个个微三角形执行光线追踪交叉检测,在DMME出现后,DMME会根据空间一致性或者细节等级需要,对这类几何形态特别复杂的单元,生成一个基底三角形,然后系统只需要针对基底三角形执行一次光线追踪交叉检测,其余的数据可以通过置换微网络直接生成。简单来说,几何形态复杂的物体,DMME先根据情况帮系统做个简化,然后自己内部通过特殊算法(DMM)生成应有的结果。英伟达宣称,最好的情况下,DMME带来了10倍的性能提升和20倍的数据量降低。
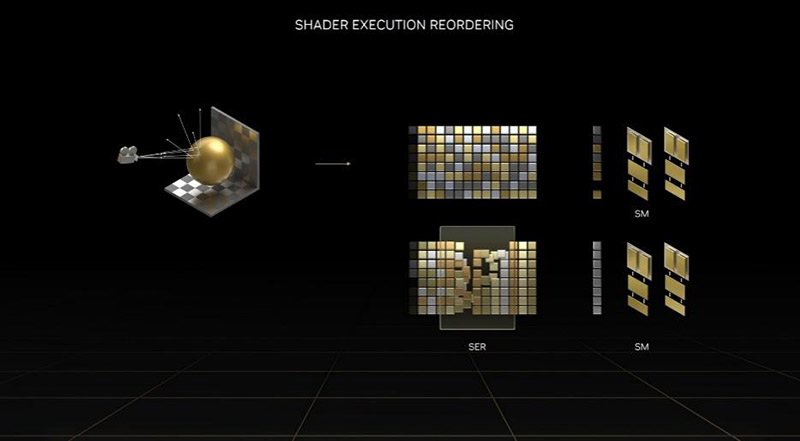
第三则是Shader Execution Reordering,直译为着色器执行重排序,简称SER。这个单元的功能解释起来是最简单的。就是在光线追踪过程中,照射到物体表面的二次光线本身是乱序的,之前的架构针对这种乱序不进行干预,需要互相等待才能完成计算,效率很低。在SER出现后,系统会根据情况,对乱序的光线计算进行排序后,再进行计算。相当于之前是一团打结的毛团,系统直接上费时又费力,现在有个单独的引擎把打结的毛团捋顺了再处理,效率就高多了。英伟达的数据是SER最多带来了2倍性能提升,实际游戏也有44%的效率改善。
更强大的AI单元:第四代张量核心
第四代张量核心的新内容其实并不多,因为这个核心是从之前的Hopper架构中移植过来的。具体来说,Ada架构的第四代张量核心相比Ampere,在大量数据计算中带来了超过2倍的张量性能,同时支持FP8 Transformer引擎等,计算性能超过1.3千万亿次。
在AI部分,英伟达将大量的应用放置在DLSS 3中,现在,借助强大的AI计算能力,DLSS 3带来了超乎寻常的性能表现和极为惊人的画质表现。我们将在下文中介绍这些内容。
全面增强的AV1解码和其他特性提升
在视频编解码能力方面,新的Ada架构加入了针对AV1编解码的支持,并且由于2个NVENC单元的存在,现在Ada架构的GPU有条件满足8K@60Hz视频的AV1编码能力,或者最多4个4K@60Hz视频的AV1编码能力。
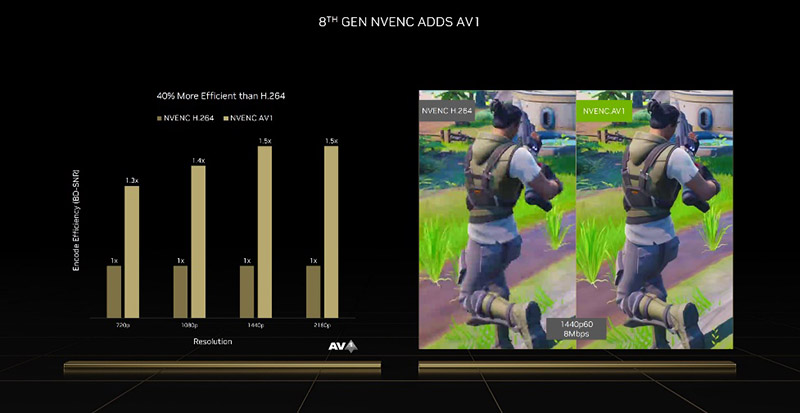
英伟达宣称,Ada架构加入的新的NVENC单元采用了全新的 AV1编码器,比采用H.264编码的视频,在效率方面提高了大约40%。这意味着新的AV1编码器带来的视频,清晰度更好,容量更小,更适合在网络或者任何带宽受限制的地方传播。
其他功能方面,目前新的视频编解码器配合软件,可以实现包括编解码能耗降低、效率提升、噪音和回音消除、虚拟背景改善等功能或者增强。软件方面目前新的Adobe Premiere Pro和剪映将会提供应用端方面的支持。

除了上述内容外,面向专业用户方面,英伟达还带来了诸如Studio应用、Racer RTX以及RTX REMIX等方面的升级。Studio应用主要是AV1编码功能带来了有关效能提升,以及达芬奇这样的软件可以利用Ada架构进行超分辨率、速度提升、AI降噪等功能了。Racer RTX是英伟达利用NVIDIA Omniverse平台,实现的一个全球游戏合作的尝试,目前有大量的软件支持NVIDIA Omniverse,全球各地的内容创作人员都可以利用它实现自己的全球工作同步。在老游戏支持方面,英伟达推出了RTX REMIX,能够为老游戏开启另外的渲染通道,并利用GPU AI特性提升纹理分辨率,让老游戏可以加入光线追踪等新技术,重新焕发新生。
无与伦比的效能和画质提升:DLSS 3全面登场
英伟达的DLSS早期是用作深度学习抗锯齿技术来使用的,主要用于替代传统的MSAA、FXAA、TRAA等,希望获得画质和性能的平衡。不过随着深度学习能力越来越强大,以及AI“脑补”的能力越来越出色,英伟达在DLSS、DLSS 2中,逐渐获得了低分辨率画面模拟高分辨率画面的能力,带来了非常卓越的性能提升。在DLSS 3中,英伟达不但继承了DLSS 2的高效率和不错的画质,还带来了强悍的帧生成能力以及延迟降低技术。
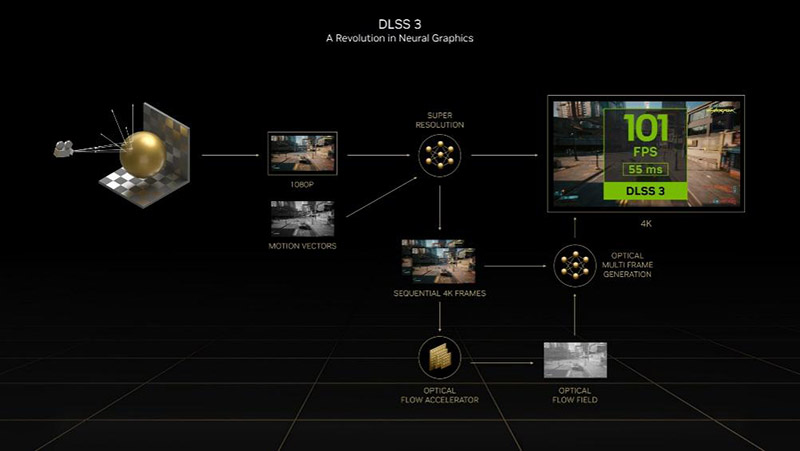
DLSS 3目前包含三个部分的内容,分别是DLSS超分辨率,也就是之前的DLSS 2的相关技术,以及DLSS帧生成技术,还有用于降低延迟的NVIDIA Reflex。其中DLSS帧生成技术是重点。

我们知道,之前的游戏画面的每一帧,都是需要CPU、GPU真正的付出算力计算而来,是实打实的“苦力活”。不过跨界来看的话,在视频处理以及传统的视觉计算应用上,存在一种叫做光流加速算法的技术,这种技术可以通过对比前后帧的差异,通过专用的模拟算法,在前后帧中间插入一帧。一般的用途在于平滑画面、减少卡顿,提高移动物体的清晰度等。
在Ada架构上,英伟达注意到了光流加速算法,在GPU中增加了更强大的光流加速器,带来了超过300 TOPS的算力,然后,英伟达结合游戏引擎的运动矢量,将游戏前一帧和后一帧的运动矢量数据,结合光流加速算法带来的插帧,实现了为游戏插入模拟帧的效果,这就是DLSS帧生成技术的由来。

英伟达提到,现在的DLSS 3,通过DLSS超分辨率技术,能够只需要一个原始帧1/4的像素值,就生成1个原始帧所有的数据,然后再通过DLSS帧生成技术,再生成一个新的帧,这相当于只需要原始1/8的数据,就得到了2个真正的游戏帧,周而复始,大幅度提高了整个游戏的效能。在CPU受限的情况下,DLSS 3也能够以2倍帧率的方式进行渲染,大大提升了游戏的流畅程度。

此外,之前针对游戏降低延迟的NVIDIA Reflex技术,是需要游戏厂商单独支持的,现在英伟达直接将其集成在DLSS 3中,这就使得支持DLSS 3的游戏,将同时支持DLSS超分辨率、DLSS帧生成以及NVIDIA Reflex,更大程度的简化了操作,提升了玩家的方便程度。英伟达目前宣称已经有35款游戏支持DLSS 3,并且DLSS 3已经加入了UE和UNITY引擎,新游戏方面诸如《超级人类》(SUPER PEOPLE)、《生死轮回》(Loopmancer)、《逆水寒》“拂云庭“(Justice ‘Fuyun Court’)、《微软模拟飞行》(Microsoft Flight Simulator)、《瘟疫传说:安魂曲》(A Plague Tale: Requiem)等游戏,都已经或正在完成对DLSS 3的支持。
显卡方面,DLSS 3需要RTX 40系列显卡才能完全支持,DLSS超分辨率技术则RTX 30、RTX 20系列显卡就可以支持,NVIDIA Reflex则GeForce 900以后的显卡都能支持。
平心而论,现在全新的DLSS 3技术,带来了视觉计算发展史上又一次重要的技术创新,未来显卡将不再以单纯的SM核心等所拥有的的算力去对抗游戏发展,通过DLSS 3另辟蹊径,AI也可以加入游戏画面生成中来,算力只需要带来一部分画面原始数据即可满足流畅运行游戏的需求,极大地改变了视觉计算发展的角度和方式,堪称一次革命。
实战测试:七彩虹iGame RTX 4090火神OC闪亮登场
在洋洋洒洒的大量介绍内容结束后,我们就我们收到的这款七彩虹iGame RTX 4090火神OC显卡进行有关RTX 4090的性能和DLSS 3、相关功能的评测。在评测开始之前,先来看看这款iGame RTX 4090火神OC的信息和情况。

七彩虹现在已经是英伟达在大陆市场的最高等级AIC,有权利拿到最先发布的芯片并推出自己的独特设计。这一次RTX 40系列显卡发布,七彩虹就在第一时间拿出了自己iGame旗下的顶级产品,也就是我们看到的这款iGame RTX 4090火神OC显卡。这款显卡的独特特性有以下几个方面:


首先是本次七彩虹带来了iGame Vulcan“智屏”,屏幕分辨率提升到800×216,并且将以前只能和显卡连体使用的显示屏,通过特殊的触点磁吸连接,或者USB底座连接,能够直接放置在显卡侧面、顶部或者干脆通过延长线放在桌面上使用。配合iGame Center控制中心软件,用户可以在屏幕上选择显示时间、不同的场景、内容、自定义的图片,以及显卡目前的状态参数,包括CPU和GPU的温度、频率、使用率、转速等,非常有趣。

其次,在特殊的功能之外,iGame RTX 4090火神OC还在延续上代火神显卡特色的基础上,带来了全新设计的外观。整个显卡看起来类似“性能猛兽”,充满锐利三角和金属元素,赛博朋克风格非常引人注目。

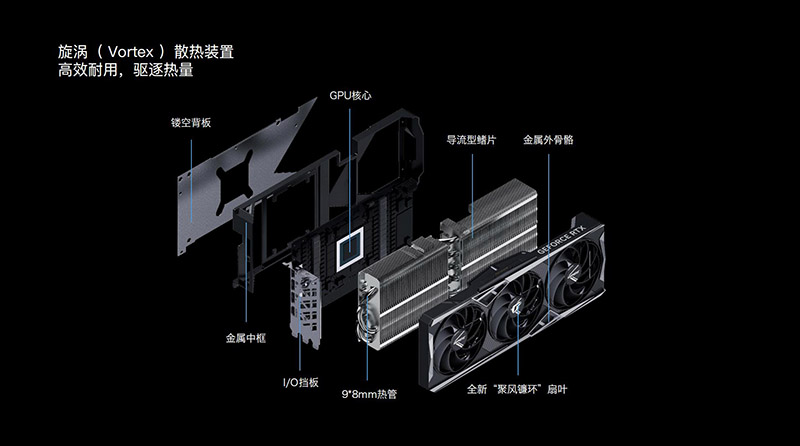
第三,在散热方面,iGame RTX 4090火神OC拥有全新的“聚风镰环” 扇叶以及9根φ8热管组件。新的散热组件采用104mm大口径9翼、双滚珠轴承三风扇设计,使空气形成漩涡聚风吸入,提升风压,增加进风量,也拥有出色的噪音控制和更长的寿命。

散热模组方面,这款显卡采用真空腔均热板也就是“真空冰片”技术,配合9根8mm的回流焊热管,以及超大面积的散热鳍片,带来了极为优秀的散热、导热效果。

第四,在显卡本体方面,为了保护脆弱的PCB和上面的元件,iGame RTX 4090火神OC采用了全铝合金中框设计,整体更为坚固。并且显卡拥有全金属外壳和背板设计,结实可靠,经久耐用。
第五,在性能方面,iGame RTX 4090火神OC拥有七彩虹特色的一键OC功能,通过按键超频,iGame RTX 4090火神OC的频率将从英伟达默认的最大2520MHz提升至2625MHz,进一步提升了显卡的性能,且方便的操作令人满意。

在介绍完显卡之后,我们就以iGame RTX 4090火神OC为核心,搭建一套测试平台。测试平台的配置如下:
- 显卡:七彩虹iGame RTX 4090火神OC(Boost 2625MHz)
- CPU:AMD 锐龙9 7900X
- 主板:技嘉AORUS X670E XTREME
- 内存:Kingston FURY(野兽)Beast RGB DDR5 6000 16GBx2
- SSD:Kingston FURY叛逆者(Renegade)NVMe SSD 1TB
- 电源:Segtop鑫谷 GM1000W ATX 3.0电源
- 操作系统:Windows 11 21H2
- 驱动:英伟达GameReady 521.90,FrameView 1.4.8127




基准和传统游戏测试部分
这部分主要是采用3DMARK测试,我们在上述平台上进行了多项测试。由于没有RTX 3090Ti作为对比,因此我们根据之前的测试成绩,给出了RTX 3090Ti在同样测试条件下的估计值,虽然这个数据不能很精确,但是也基本靠谱,可以用于衡量RTX 4090在基准测试中的进步幅度。另外,我们还加入了一款传统游戏也就是《古墓丽影:暗影》,因为这款游戏自带Benchmark、光线追踪和DLSS,因此经常被用来测试,我们也将4K、自带的最高画质下RTX 3090Ti可以达到的性能水平使用过往经验进行了预估,同样用于对比RTX 4090的进步情况。
测试成绩汇总表如下:
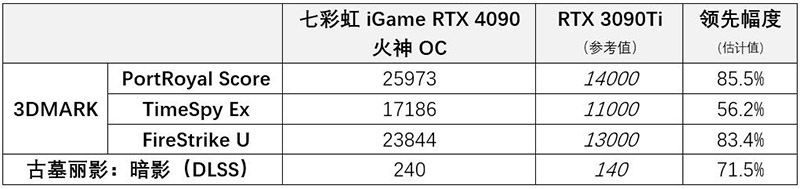
从3DMARK以及《古墓丽影:暗影》的测试情况来看,考虑到AD102相比GA102,在规模、频率、架构上进步如此之多,因此在这类传统测试中,除了TimeSpy Ex测试外,RTX 4090在其他测试中,领先幅度高达70%~80%,是完全在我们估计之内的。在使用了工艺红利以及英伟达在架构上如此给力之后,这样的性能真是令人喜闻乐见。
除了上述传统测试外,我们还进行了一些专项内容测试,截图分列如下:
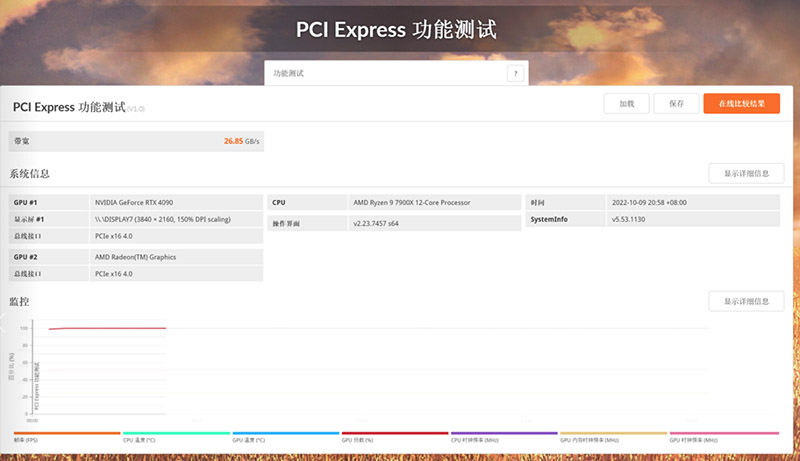
在3DMARK的PCIE功能测试中,读取到的最大带宽为26.85GB/s。目前RTX 4090支持PCIe 4.0,但是X670E主板和AMD 锐龙9 7900X支持PCIe 5.0,最大能提供128GB/s的带宽,可能是3DMARK很多年没有更新这个测试内容了,因此整体测试下来,完全不能喂饱带宽物理规格。
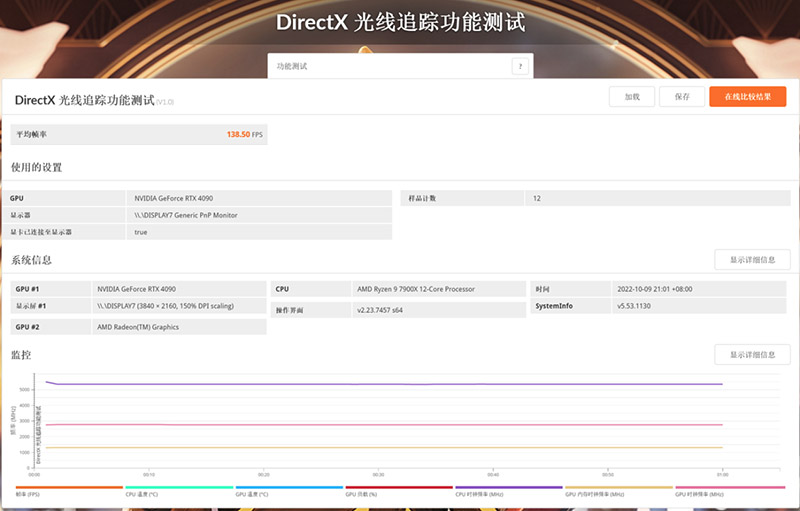
在DirectX光线追踪专项测试中,RTX 4090给出了138FPS的成绩,相比之下,RTX 3090Ti的性能大约在60fps左右,这方面RTX 4090进步极为巨大。
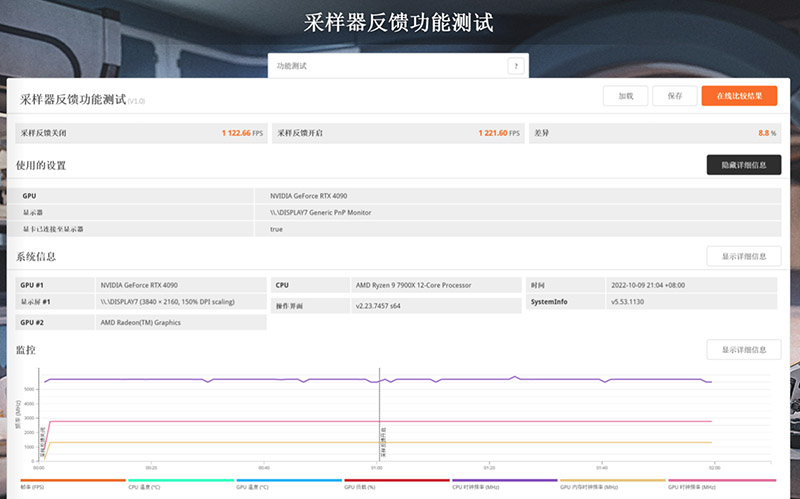
在采样器反馈功能测试中,RTX 4090得到了1122.66fps,并且开关这个测试压力不算大,RTX 4090的计算资源是如此的宽裕,令人惊讶。
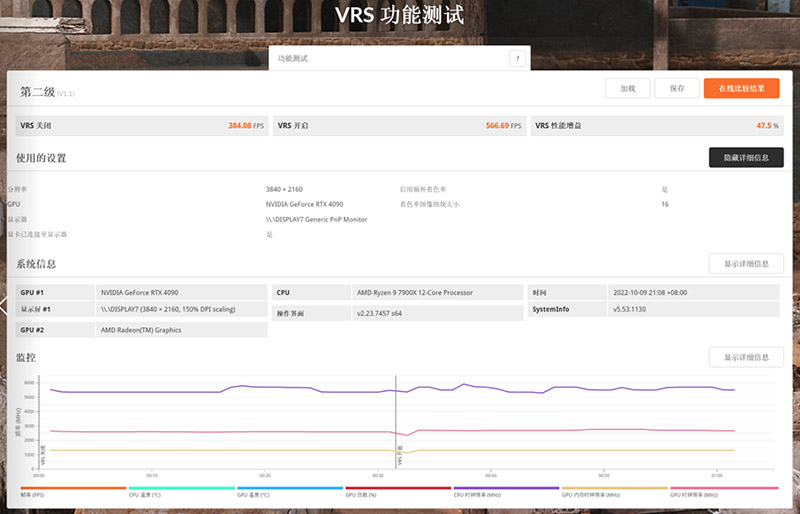
VRS功能测试也是展示GPU在VRS可动态调整分辨率方面的效能,这个测试得出了47.5%的性能增益,开启VRS后RTX 4090帧率高达384.08fps,整体表现是很不错的。
最后,由于七彩虹iGame RTX 4090火神OC是一款OC后的显卡,频率比公版略高,我们将其频率降低至和公版显卡一样,对比性能差异。
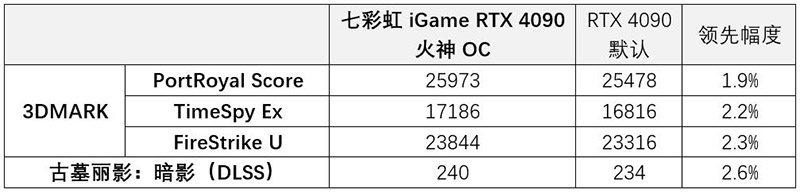
可以看出,超频前后,七彩虹iGame RTX 4090火神OC相比官方频率,大概提升了2%~3%,虽然不大,但也非常不错了,毕竟这是官方OC,相对要更加保守一些。
DLSS 3体验和性能测试
DLSS 3体验和性能测试是本次测试的重头戏。我们选取了6款游戏进行性能测试和视频、画质对比,分别是《赛博朋克2077》、《F1 22》、《逆水寒》、《瘟疫传说:安魂曲》以及两个游戏引擎给出的对比测试,分别是Unity Enemies以及UE LyraGame。
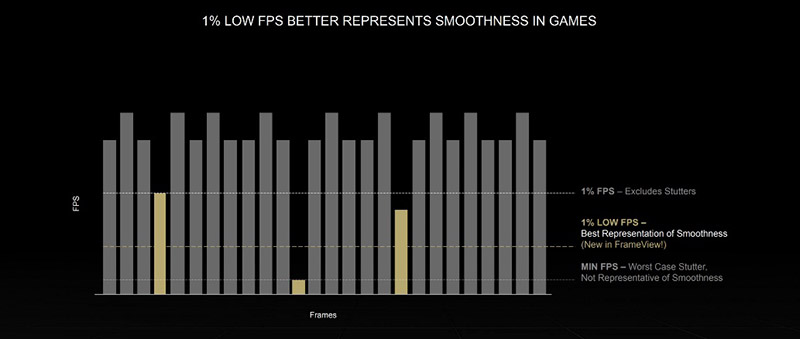
在测试开始之前,我们先来了解一下1% Low FPS和新版本的FrameView。
英伟达在本次测试中,特别提到了1% Low FPS的概念。众所周知的是,目前我们衡量显卡的性能一般使用平均FPS,这个数据可以反应显卡在一段时间内计算帧率的能力。但是对玩家至关重要的流畅性而言,平均FPS概念可能不太合适。

人眼是非常敏锐的,能够分辨的时间间距大约是数十毫秒。对游戏而言,平均帧率在60fps,生成每一帧的时间大约是16.6ms(1000/60)。但是,问题在于这个生成每一帧的时间是个平均值,如果一秒内有那么一两帧的画面,需要100ms才能生成,又有一些帧几毫秒就生成了,那么对100ms生成的那些帧而言,人眼就会显著感觉到卡顿和不流畅。
鉴于此,业内提出了1% Low FPS的概念,就是把游戏测试过程中,帧生成时间最长的那1%的帧所耗费的时间统计出来,然后再转换成FPS也就是每秒帧率,使用这个数据和平均帧率相比,如果1% Low FPS非常靠近平均帧率,那证明游戏流畅性相对非常出色,如果差距很大的话,可能就很不令人满意了。
为了更好的体现1% Low FPS的作用,目前英伟达提供了新版的FrameView,直接可以在屏幕上显示出1% Low FPS数据,通过其采样、录制帧率后,也会直接给出1% Low FPS,以及整体游戏的延迟。
对DLSS 3而言,通过游戏深入优化,以及NVIDIA Reflex技术,能有效降低游戏延迟,提升游戏流畅程度。接下来我们就拥六款游戏测试来体验一下。
《赛博朋克2077》:DLSS 3画质更好,性能更卓越
首先来看《赛博朋克2077》,这款游戏目前的测试版本可以开启DLSS 3,实际测试数据我们用柱状图表示在下方。

从测试结果可以看出,在4K分辨率、最高画质下,不开启DLSS 3的时候,整体延迟高达93ms,帧率也仅为38FPS,游戏可玩性是非常差的。但是在开启了DLSS任何一个模式后,帧率都会提升到100FPS以上,尤其是比较均衡的性能模式,帧率更是来到了140帧之多,延迟也仅为37ms,游戏可玩性得到了根本性改善。
游戏画面对比方面,我们给出了2段视频,分别是原生画质和DLSS 3 性能模式的画质。




从画质对比来看,DLSS 3模式下的画质出现了比原生画质更清晰的“悖论”,说它是悖论的原因,是因为DLSS 3模式的画质是通过AI用原生低分辨率画质“生成”的,结果这样处理的画质,反而比原生画质更清楚。当然还有一种非常重要的原因是由于原生模式下帧率不足,因此在动态模糊等作用下,原生画质显得比较糊,而高达140帧的DLSS 3模式,则清晰异常。尤其是在纹理、边缘等地方,DLSS 3的画质表现都更胜一筹。
《F1:22》:DLSS 3性能更好,文字更清晰
接下来是游戏《F1:22》,这是一款今年才上市的赛车类游戏,其特点在于画质出色。我们还是先来看性能。
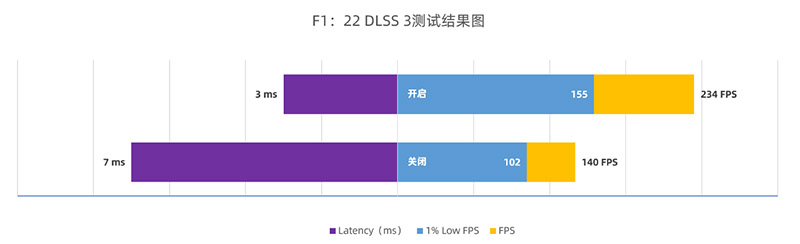
这款游戏本身在RTX 4090下的帧率就高达140帧,在DLSS 3加持后,帧率进一步提高到了243帧,延迟也从7ms降低至3ms,整体表现非常合理。
画质对比方面,DLSS 3画质似乎比原生画质更为精细一些,尤其是右边的字牌上的字,DLSS 3的字体边缘更清晰,不发虚,这一局对比又是DLSS 3胜利。
《逆水寒》:DLSS 3性能暴增,画质不错
逆水寒本次也加入了DLSS 3的测试项目,我们看看它在开启DLSS 3后的性能情况。
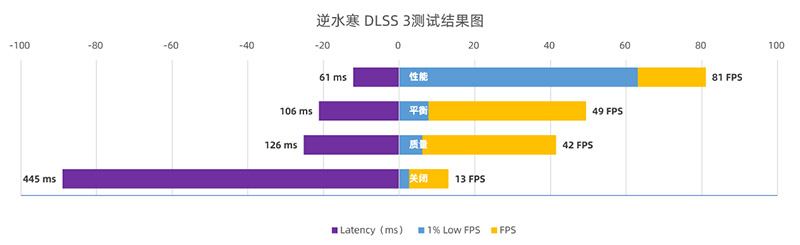
从测试情况来看,原生未优化的情况下,逆水寒在RTX 4090上只有13FPS,延迟也高达445ms,完全丧失了可玩性。在DLSS 3质量和平衡模式下,整体效果大有改善。最好的还是DLSS性能模式,帧率飙升至81帧以上,延迟也降低至61ms,完全流畅了。



在《逆水寒》DLSS 3的画质对比中,DLSS 3的性能和平衡模式下,画质相比原生画质略微模糊,尤其是上方的灯笼纹理模糊是比较明显的,其余部分也有略微模糊的迹象出现。不过考虑到DLSS 3带来了巨大的性能提升,这一点已经完全可以忽略了。
《瘟疫传说:安魂曲》:DLSS 3性能更上一层楼
《瘟疫传说:安魂曲》最新的版本也加入了DLSS 3,不过目前还在测试过程中,因为是测试版本,所以游戏经常崩溃,我们只是简单测试了一段路程的性能,就没有做多的画面对比截图了。
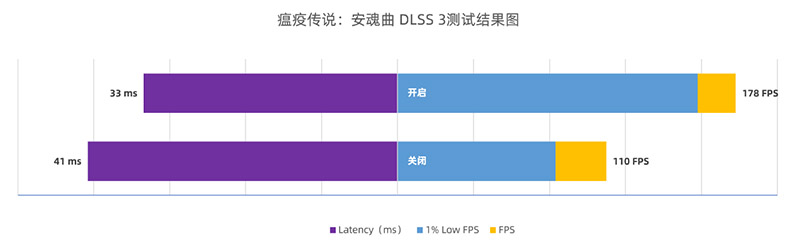
从性能测试来看,在DLSS 3加入后,这款游戏的性能又有了进一步提升,考虑到这是RTX 4090,如果是RTX 4060的型号的话,DLSS 3应该可以让游戏从不流畅变成流畅,可玩性也大幅度提升。延迟方面,DLSS 3的加入让延迟进一步降低了,非常不错。
UE LyraGame:DLSS性能卓越,画质优秀
因为英伟达要把DLSS 3嵌入到UE引擎中,因此UE也专门推出了一个测试版本的小游戏,用于展示DLSS 3的性能。首先来看实测的性能情况。
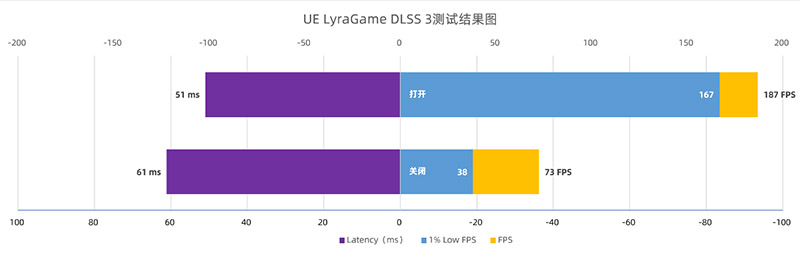
实际测试下来,DLSS 3的性能基本上是翻一番还有余,和之前的游戏以及测试差不多情况,整体效能非常卓越。

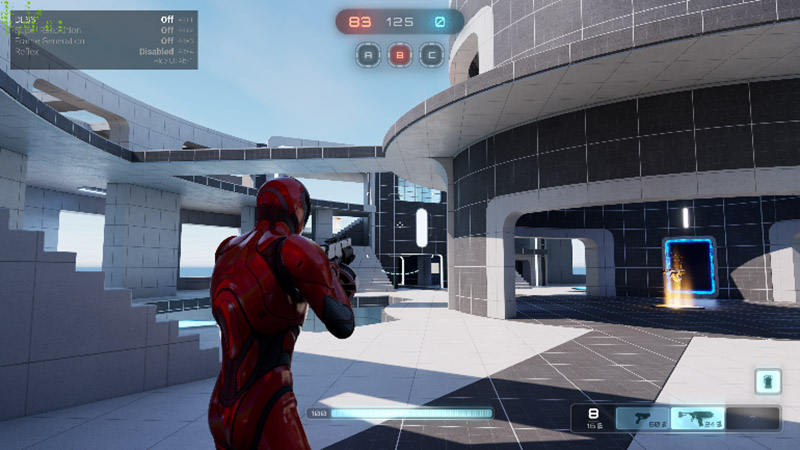
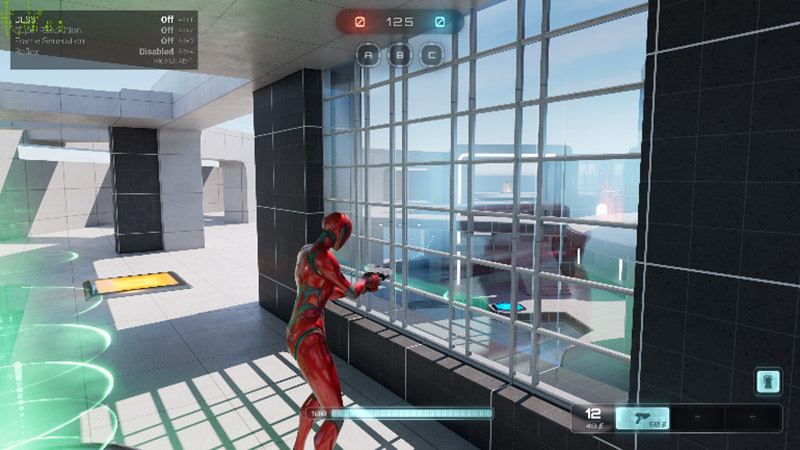
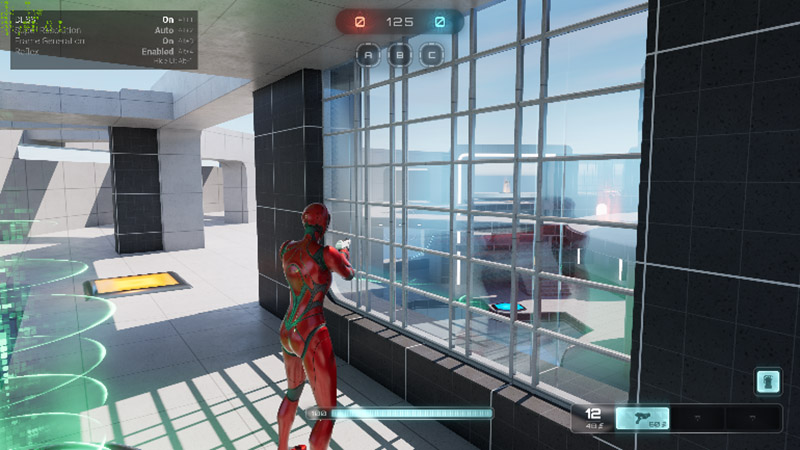
从整体画质来看,DLSS 3开启和关闭对游戏画质影响非常小,都保持了和原生一样的水平。不过值得注意的是,玻璃中人物和周围物体的倒影,在DLSS 3开启后,出现了一定程度的质量损失,可能是低分辨率下的原生图像质量也比较差的原因,这是DLSS 3在这里出现的一点瑕疵,不过这个瑕疵非常微小,不是很注意的话也不容易发现,也完全不影响游戏体验,希望在后期可以改善。
Unity Enemies:DLSS 3性能大幅度提升
Unity Enemies是Unity拿出的DLSS 3 Demo,和UE集成DLSS 3的目的是一样的。这个测试Demo的内容做得非常精致,甚至给人一种看电影的感觉。性能方面,DLSS 3带来了超过100%的性能提升,延迟也大幅度降低。
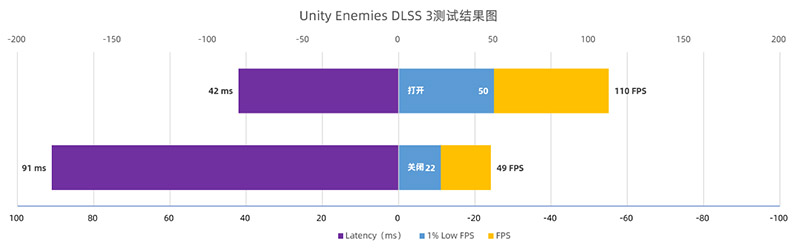
由于这个Demo不是很方便截图,因此我们只是放一些图片用于大家欣赏。


写在最后:DLSS 3——RTX 4090系列的杀手锏
实际纵观整个测试来看的话,RTX 4090和Ada架构给我们带来的感觉,就是无与伦比的强悍,当然,以英伟达目前的技术能力和业内地位来说,这样的强悍是应该的。在换用了全新的工艺,大幅度提高了晶体管密度至每平方毫米1.25亿个之后,这颗AD102有这样的性能表现,尤其是在3DMARK中的性能表现,其实我们是一点也不惊讶的。
最大的惊讶来自于DLSS 3,这简直是一场“无中生有”的魔术,利用DLSS 3,英伟达用1/8算力和AI搭配,完成了之前需要当前8倍算力才能完成的画面计算任务,并且得到了如此优秀的画质和效能——是的,我们在这六款DLSS 3游戏的测试中,是完全挑不出DLSS 3任何一点毛病的。可能有人说它的画质在某些情况下有点瑕疵,那又怎么样呢?这一点在游戏中根本感受不出来,换取2~4倍的性能提升,是谁都愿意吧?可能又有人说,开了DLSS 3后游戏延迟变高。的确,DLSS 3有一半的帧率是AI“脑补”出来的,不是真实计算出来的(这部分帧的作用只能平滑画面),但是,不是还有2倍的帧率提升是真实的啊!帧率越高,延迟越低,DLSS 3宣称也是让帧率提升4倍,延迟降低2倍,没说延迟也降低4倍啊。所以,你不得不佩服英伟达。
此外,如今的英伟达已经牢牢把控游戏产业生态圈,地位不可动摇,从UE和UNITY已经集成DLSS 3引擎就能看出。本来NVIDIA、AMD和Intel三家公司还在比拼算力,结果英伟达“不讲武德”,直接动用AI下场。竞争对手原本帧率落后20-30%,显卡还可以降价卖,但是现在差距是1倍、2倍,怎么卖?所以说DLSS 3,才是整个RTX 40显卡和Ada架构的那片“二向箔”,不讲武德,但值得期待。












