横排-无底-140x48mm-04-1.png "前沿科技阵地")
竖排-无底白字-280x96mm-04.png "前沿科技阵地")

在阿里通义今晨发布Qwen3-VL系列新成员Qwen3-VL-4B和Qwen3-VL-8B之际,英特尔于今日同步宣布,已经在酷睿 Ultra 平台上完成对这些最新模型的适配。此次Day 0支持延续了十天前对Qwen3新模型快速适配的卓越速度,再次印证了英特尔在加速AI技术创新、积极构建模型合作生态方面的深度投入与行动力。
此次发布的Qwen3-VL系列新模型,在延续其卓越的文本理解和生成、深度视觉感知与推理、更长的上下文长度、增强的空间与视频动态理解及强大代理交互能力的同时,凭借其轻量化的模型参数设计,在英特尔酷睿Ultra平台上可以实现高效部署,为复杂的图片和视频理解及智能体应用带来更出色的性能与体验。
为确保用户能够获得更流畅的AI体验,英特尔在酷睿Ultra平台上,对Qwen3-VL-4B 模型进行了创新的CPU、GPU和NPU混合部署,充分释放了XPU架构的强大潜力。通过精巧地分解并优化复杂的视觉语言模型负载链路,并将更多负载精准调度至专用的NPU上,此次英特尔的Day 0支持实现了:
- 显著的能效优化:大幅降低CPU占用率,更好地支持用户并发应用。
- 卓越的性能表现:在混合部署场景中,模型运行吞吐量达到22.7tps。
- 流畅的用户体验:充分利用酷睿Ultra的跨平台能力,提供无缝的AI交互。
以下的演示视频充分地展示了该成果:Qwen3-VL-4B模型在图片理解与分析任务中,在高效利用NPU算力的同时,显著降低了CPU的资源占用。
(演示视频: 在英特尔在酷睿Ultra平台上,Qwen3-VL-4B释放系统资源带来流畅体验)
快速上手指南
第一步 环境准备
基于以下命令可以完成模型部署任务在Python上的环境安装。
python -m venv py_venv
./py_venv/Scripts/activate.bat
pip uninstall -y optimum transformers optimum-intel
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 –index-url https://download.pytorch.org/whl/cpu
pip install git+https://github.com/openvino-dev-samples/optimum.git@qwen3vl
pip install git+https://github.com/openvino-dev-samples/transformers.git@qwen3vl
pip install git+https://github.com/openvino-dev-samples/optimum-intel.git@qwen3vl
pip install –pre -U openvino –extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly
该示例在以下环境中已得到验证:
- 硬件环境:
- 英特尔® 酷睿™ Ultra 7 258V
- iGPU驱动版本:32.0.101.6733
- 内存: 32GB
- 操作系统:
- Windows 11 24H2 (26100.4061)
- OpenVINO版本:
- openvino 2025.3.0
第二步 模型下载和转换
在部署模型之前,首先需要将原始的PyTorch模型转换为OpenVINOTM的IR静态图格式,并对其进行压缩,以实现更轻量化的部署和最佳的性能表现。通过Optimum提供的命令行工具optimum-cli,可以一键完成模型的格式转换和权重量化任务:
optimum-cli export openvino –model Qwen/Qwen3-VL-4B-Instruct –trust-remote-code –weight-format int4 –task image-text-to-text Qwen3-VL-4B-Instruct-ov
开发者可以根据模型的输出结果,调整其中的量化参数,包括:
- –model: 为模型在HuggingFace上的model id,这里也提前下载原始模型,并将model id替换为原始模型的本地路径,针对国内开发者,推荐使用ModelScope魔搭社区作为原始模型的下载渠道,具体加载方式可以参考ModelScope官方指南:https://www.modelscope.cn/docs/models/download
- –weight-format:量化精度,可以选择fp32,fp16,int8,int4,int4_sym_g128,int4_asym_g128,int4_sym_g64,int4_asym_g64
- –group-size:权重里共享量化参数的通道数量
- –ratio:int4/int8权重比例,默认为1.0,0.6表示60%的权重以int4表,40%以int8表示
- –sym:是否开启对称量化
第三步 模型部署
除了利用Optimum-cli工具导出OpenVINO模型外,我们还在Optimum-intel中重构了Qwen3-VL和Qwen3-VL-MOE模型的Pipeline,将官方示例示例中的的Qwen3VLForConditionalGeneration替换为OVModelForVisualCausalLM便可快速利用OpenVINO进行模型部署,完整示例可参考以下代码流程。
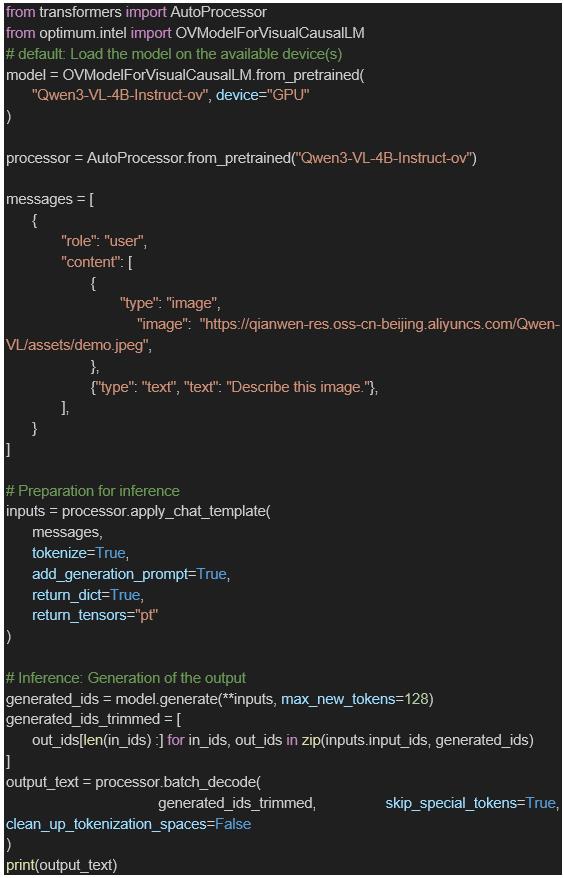
以下为该模型在图像理解任务中的输出示例:

‘This is a heartwarming, sun-drenched photograph capturing a tender moment between a woman and her dog on a beach at sunset.\n\n**Key Elements:**\n\n* **The Subjects:** A young woman with long dark hair, wearing a plaid shirt, sits on the sand. Beside her, a large, light-colored dog, likely a Labrador Retriever, sits attentively, wearing a harness. The two are engaged in a playful, paw-to-paw high-five or “pawshake” gesture, a clear sign of their bond.\n* **The Setting:** They are on a wide, sandy beach.
| CPU 代号名 | 设备 | 模型 | 精度 | 输入规模 | 输出规模 | 第二个+ token/秒 |
| Lunar Lake | 英特尔酷睿Ultra 7 258V(XPU) | Qwen3-VL-4B-Instruct | NF4 | 656(1024 for LLM) | 128 | 22.7 |












