横排-无底-140x48mm-04-1.png "前沿科技阵地")
竖排-无底白字-280x96mm-04.png "前沿科技阵地")

前段时间,谷歌机器感知(Google Machine Perception)团队与 Daydream Labs 和 YouTube Spaces合作,为混合现实提供了“头显摘除”解决方案,用机器学习重现被头显遮挡的脸,解决 MR 视频的痛点。这项研究使用集成了眼球追踪技术的头戴显示器,可以展现一个玩家丰富的面部表情。脸部表情是理解一个人在虚拟现实体验情绪的关键,它传达着重要的社交活动线索。
今天,我们提出了一种方法,通过分析脸部一小块区域来推断整个面部表情。具体来说,我们在虚拟现实头显中装入红外摄像头,用于捕捉用户眼睛区域,这足以推断至少一部分面部表情,而无需使用任何外部摄像头或额外的传感器。
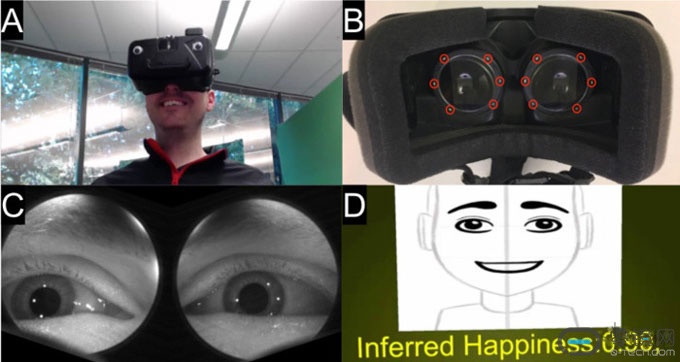 左边:一个用户戴着虚拟现实头显,使用眼球追踪来进行表情分类。
左边:一个用户戴着虚拟现实头显,使用眼球追踪来进行表情分类。
右边:从监测到的眼睛图像匹配我们的模型,从而推断表情的表达。
我们使用深度学习来区分眼睛和周围区域的面部表情,这些区域通常包括虹膜、巩膜和眼睑,还可能包括眉毛和脸颊部分。从这样的新型传感器中获取大量的数据是一项具有挑战性的任务,因此我们收集了 46 个实验对象的一系列面部表情训练数据。
为了达成脸部表情分类,我们微调了 TensorFlow 的 Inception 变体,并在 Imagenet 上训练了模型的权重。由于参与者的外貌差异,我们试图在一定程度上消除这些差异。
我们已经证明了,这种方式对于各种面部表情的识别是可靠的,而且捕获眼睛区域的这些信息可以通过使用基于 CNN 的方式进行解码,即使对人类来说,仅从眼睛区域识别面部表情也是十分重要的。我们的模型可以实时进行推断,并可以实时生成带有面部表情的头像,它可以用作虚拟现实用户的社交表达的替代。这种交互机制还能产生一种更直观的界面,例如在虚拟现实中分享表情,取代以前的手势或键盘输入。
目前的眼球追踪技术可完全嵌入到消费者 VR 头显中,而无需额外的外部摄像头,这种方式捕捉用户面部表情是一个可以移动的解决方案。这种技术的发展超越了动画卡通头像,它可以用来提供更丰富的“头显摘除”体验,通过更真实和更丰富的情感信息来增强虚拟现实的交流和社交活动。










