横排-无底-140x48mm-04-1.png "前沿科技阵地")
竖排-无底白字-280x96mm-04.png "前沿科技阵地")

今年的Siggraph大会即将落下帷幕,各路VR/AR公司在本次大会上都拿出了自己的看家本领一较高下。
技术类文章也是百花齐放,各种新兴技术让人目不暇接,但是有一篇文章可谓万众瞩目,它提供的技术仿佛让大家看到了VR/AR显示内容的未来,或许未来有一天我们可以在VR/AR设备里看到三维的体育赛事或者歌坛天后演唱会的现场直播,你还可以随便“加特技”。
这篇最令人期待的技术类文章就是Fusion4D了。如果大家还记得伴随着微软的Hololens宣传视频一起出来的那个叫Holoportation的视频,当初一定惊讶于这项神奇的4D重建技术吧。Fusion4D就是Holoportation背后的神秘技术。
如果要用一句话描述Fusion4D做了什么,那就是Fusion4D实现了多视角下的实时动态三维重建。具体来讲,多视角就是有多个深度摄像机,可以360度无死角的对重建对象进行深度信息采集(作者搭建的实验场景使用了8台深度摄像机);实时就是重建速度达到每秒30帧以上,人眼基本看不出来卡顿现象;动态三维重建相对于静物三维重建,即三维重建的对象可以动起来,主要应用于日常生活中人的动作行为的重建,整个三维重建的目标包括还原人体几何和动作信息。
要知道以前的动态三维重建技术还局限于线下非实时处理,而且处理速度相当慢,有时处理一帧深度图像要花数分钟,这样算来一个几百帧动作序列的重建工作可以花上好几个小时,显然根本无法满足现场直播的需求。直到华盛顿大学的Richard Newcombe在去年的CVPR大会上发表了一篇叫DynamicFusion的文章,大家第一次看到实时三维重建的可能,该文章也凭借这个突破性进展获得了那年的最佳论文奖。
可是DynamicFusion只能针对一个深度摄像机进行实时三维重建,无法完整复原重建对象的整个三维信息,并且不能有效地处理拓扑结构改变的情况。而Fusion4D很好地解决了DynamicFusion存在的各种问题,把实时三维重建推向了一个新的高度。
该论文的主要贡献有:
1)基于ED(embedded deformation)变形模型提出了一个用来估计非刚性变形场的能量方程,并针对该方程能量优化的特点提出了基于GPU的实时演算方法;
2)提出了基于机器学习的对应点查找方法(correspondence point search)
3)提出了一个能够适用于复杂场景的多个摄像机深度信息的融合(data fusion)方法,这种复杂场景包括快速的动作(比如武术动作)或者重建对象拓扑结构的改变(比如脱下外套)。
下面我来逐一简单介绍这几项关键技术,具体细节请参考论文原文“Fusion4D: Real-time Performance Capture of Challenging Scenes”。
(注:文中【1】、【2】、【3】。。。为参考文末文献)
ED变形模型由苏黎世理工(ETH Zurich)的Robert Sumner在2007年提出,用来对模型做非刚性变形【1】该方法根据模型建立了一个变形网格,网格上的每一个节点负责驱动它控制范围内的模型顶点进行变形(如下图)。后来Hao Li等人发掘了该方法在三维重建领域内的潜力,利用ED变形模型成功地解决了三维重建中非刚性形变物体的点云配准问题(Point cloud registration),但是他们还无法达到实时重建【2】。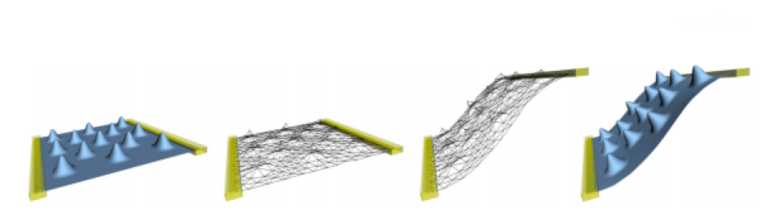 直到上面提到的Richard Newcombe在他的文章“DynamicFusion”中根据提出的能量方程和Gauss-Newton优化方法的特点,结合GPU把三维重建加速到了实时,从而为Fusion4D实现更复杂场景下的实时三维重建打下了基础。在Fusion4D提出的能量方程中,除了ED变形模型里使用到的三个能量项外,额外添加了一个点对对应关系(correspondence)的能量项和限制可视范围(visual hull)的能量项。
直到上面提到的Richard Newcombe在他的文章“DynamicFusion”中根据提出的能量方程和Gauss-Newton优化方法的特点,结合GPU把三维重建加速到了实时,从而为Fusion4D实现更复杂场景下的实时三维重建打下了基础。在Fusion4D提出的能量方程中,除了ED变形模型里使用到的三个能量项外,额外添加了一个点对对应关系(correspondence)的能量项和限制可视范围(visual hull)的能量项。
visual hull这一项主要把能量方程解的范围限制在这8个摄像机重合的视锥体范围内,有效地解决了遮挡问题出现时解空间太大的问题(visual hull如何确定如下图)。点对对应关系根据文章【3】里的方法进行了改进,作者采用了基于决策树的机器学习模型寻找相邻两帧RGB图像之间的对应点点对关系。
通过训练集决定最优的split函数,测试时根据决策树上每个节点的split函数最终把每一个像素点分到一个叶子节点中,处于同一个叶子节点的两个像素被认为是具有对应关系的点对。在对能量方程优化求解时,作者针对Levenberg-Marquardt方法中矩阵呈现方块化稀疏分布的特点,提出了基于GPU的分布式计算方法。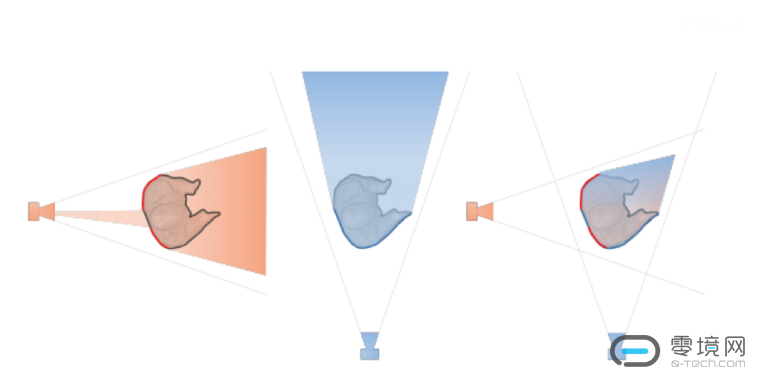
数据融合方法最初由Brian Curless和Marc Levoy提出,用来实现基于图像的三维重建(如下图)【4】。随着微软Kinect的推广,该技术被大量用在了基于点云的三维重建中,其代表文章为KinectFusion,作者依然是我们的“Newbe”哥——Richard Newcombe【5】。对于这项技术最贴切的一个比方就是米开朗基罗是如何在一块长方体大理石上雕刻出大卫的。
我们开始假设有一个可以包围整个重建对象的Volume,这个Volume由n*m*l个均匀大小的体素(voxel)构成,这好比是开始雕刻之前的那块原石。然后我们通过点云配准把点云放在和该Volume统一的一个世界坐标系下,再计算每个体素到点云上最近点的距离,当然距离太远的体素我们没有必要更新它的距离值,我们只关心距离接近于0的那些体素,因为物体的真正表面是距离为0的那些位置。
由于体素上的距离值不一定正好是零,我们可以通过插值的方式在每一个体素内部找到距离正好为0的点,这个过程可以由Marching Cubes方法实现。这就好比我们根据大卫表面上每个点的位置,凿刻大理石到一定的深度,最后这样一下下的凿刻完,一个完美的大卫也就展现在了我们眼前。
Fusion4D里对Data Fusion一个很大的贡献是提出了一种融合纠错机制。即使再好的点云配准方法也不能保证百分之一百完美匹配两帧点云,当上一帧重建出来的模型不能很好地匹配到当前帧时,作者用当前帧的数据完全替代之前没有匹配好的部分,并以此进行数据融合,将得到的模型作为新的一个关键帧来替代原始的参考模型(reference model),之后的数据融合和点云配准将改为以此关键帧为准。这种方法有效地解决了当点云配准不准确时数据融合产生的误差。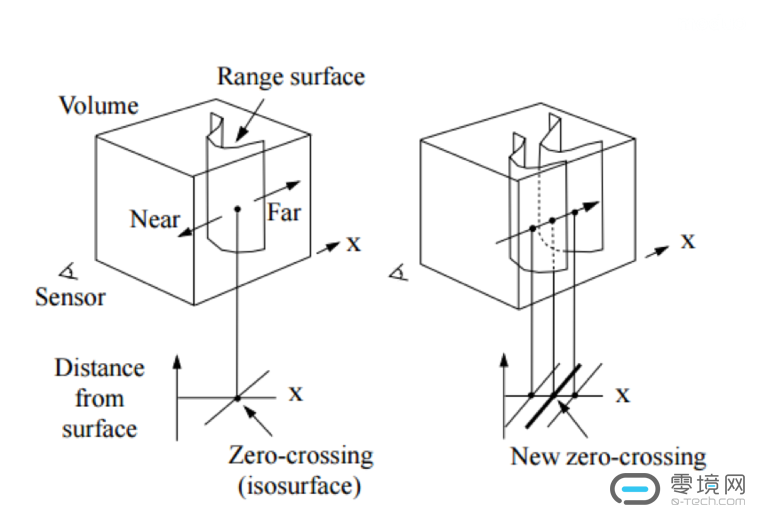 最后让我们畅想一下Fusion4D给VR/AR技术带来的革新动力,或许在不久的将来我们就可以在VR/AR设备上看到4D直播了。看NBA看不清詹姆斯的炫酷灌篮动作怎么办?没关系,360的慢镜头重放,让你细细体味。天后王菲只开一场演唱会,去不了怎么办?没关系,4D直播技术带你亲临演唱会,帮你扫清一切烦恼。
最后让我们畅想一下Fusion4D给VR/AR技术带来的革新动力,或许在不久的将来我们就可以在VR/AR设备上看到4D直播了。看NBA看不清詹姆斯的炫酷灌篮动作怎么办?没关系,360的慢镜头重放,让你细细体味。天后王菲只开一场演唱会,去不了怎么办?没关系,4D直播技术带你亲临演唱会,帮你扫清一切烦恼。
图片版权均归原作者所有。
【1】Sumner, Robert W., Johannes Schmid, and Mark Pauly. “Embedded deformation for shape manipulation.” ACM Transactions on Graphics (TOG). Vol. 26. No. 3. ACM, 2007.
【2】H. Li, B. Adams, L. J. Guibas, and M. Pauly, “Robust single-view geometry and motion reconstruction,” ACM Trans. Graph., vol. 28, no. 5, p. 1, 2009.
【3】Wang, Shenlong, et al. “The global patch collider.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
【4】Curless, B. and Levoy, M., 1996, August. A volumetric method for building complex models from range images. In Proceedings of the 23rd annual conference on Computer graphics and interactive techniques (pp. 303-312). ACM.
【5】Newcombe, Richard A., et al. “KinectFusion: Real-time dense surface mapping and tracking.” Mixed and augmented reality (ISMAR), 2011 10th IEEE international symposium on. IEEE, 2011.
转自:moduo魔多












