横排-无底-140x48mm-04-1.png "前沿科技阵地")
竖排-无底白字-280x96mm-04.png "前沿科技阵地")
")
上海交大的武筱林教授和其博士生张熙可能又度过了一个夜不能寐的夜晚。他们可能还不明白,当初花费大量时间做出的研究论文,为何如今会因谷歌研究员的文章而被视为伪科学,进而再一次站在风口浪尖之上。而同样不理解的,可能还包括试图在长达两万字的批驳文章中寻找真相的读者。
长相决定你是否是罪犯

整件事情可能要从2016年11月说起。武张二人当时将他们的论文《基于面部图像的自动犯罪性概率推断》(Automated Inference on Criminality using Face Images)上传至了arXiv 上。这是一家研究者时常光顾的网站,为避免论文在收录前被他人剽窃想法,研究者往往会预先上传论文至该网站进行预收录。此外,作为论文预印本网站其也拥有一定影响力。而武张二人明显抱着相同的想法。
在论文中,武张二人采用计算机视觉和机器学习技术检测了1856张中国成年男子面部照片,其中730人被标记为罪犯。更为准确地说:
实验选取了1856张中国18到55岁男性的照片,面部无毛发遮挡、无伤疤或其他标记,并将它们归为罪犯组和非罪犯组。非罪犯组包含1126张用爬虫从互联网上抓取的照片,人群来自社会各行各业:服务员、建筑工人、司机、医生、律师、教授等。
罪犯组共730张照片,其中330张来自公安部或省级公安厅的通缉令,400张由一所与实验组达成保密协议的公安局提供。在这730名罪犯中,235名涉及暴力犯罪,包括谋杀、强奸、人身侵犯、绑架和抢劫,其余则犯下了偷窃、欺诈、贪污等非暴力罪行。所有照片都被调整为80cmX80cm大小,并对亮度和灰比进行了控制,尽量避免对结果造成影响。
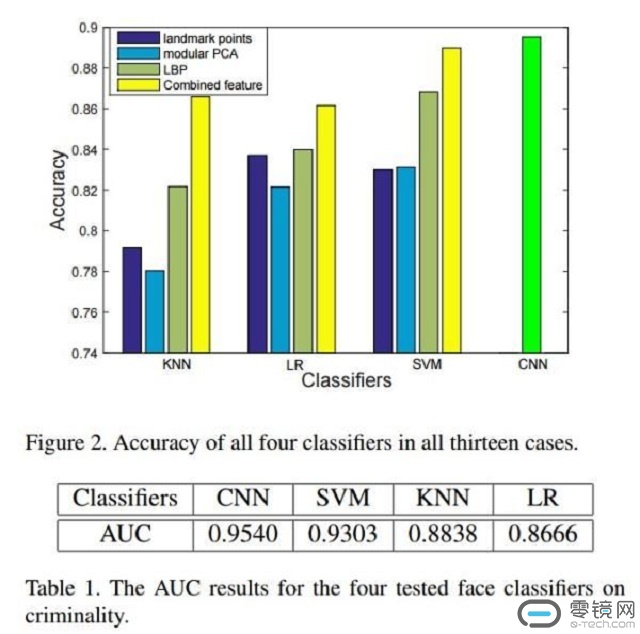
此后他们建立了四个不同的分类器(LR,KNN,SVM,CNN),以民族、性别、年龄和面部表情作为控制要素,让计算机区分犯罪者和非犯罪者。最终则得出了这样的结论:平均来讲,罪犯的内眼角间距要比普通人短5.6%,上唇曲率大23.4%,鼻唇角角度小19.6%。同时,他们发现罪犯间的面部特征差异要比非罪犯大。而这也表明,利用机器学习技术可以预测一个人是否是犯罪分子(而非犯罪嫌疑人)。武张二人更是表示,利用该技术预测的准确度几乎高达90%。

在正常论文发表中,往往会经过同行评议,由于是发表在arXiv上,所以缺少了这一过程。虽并未正式发表,但调查结果仍旧引发了国内外大量新闻报道。而武张二人也收到了大量来信,其中有索取实验细节交流看法的,也有对其进行攻击性回应的。来自康奈尔大学的同行就表示,“我是来敦促你撤稿的,因为这是一项可耻的工作。我们无法选择自己的唇部弧度、眼间距和所谓的鼻唇角角度。但犯罪者的问题在于行为,而不是长相。”
而武教授显然对这些来信感到气愤不已,并表示“有些人站在道德高地谴责我制造歧视,部分言论明显带着对中国学者的偏见。我很生气,这本来是一个纯粹的科学问题!”而最初做这样的论文,正是为了对长期存在的“相由心生”的问题进行证伪,“最开始,我们是抱着怀疑的态度,想用现代科学方法去证伪这种观点。”但是得到的结论却使他们感到意外。
也因此,他们会在一年后才公布当时的结论。而在这一年中,他们也在各个角度质疑自己的研究。甚至听取建议,在警察提供的罪犯照片的光学信号上增添噪音,从而消除与抓取的照片之间的差异。尽管误判率升高,但此前的结论仍得以保留,准确率仍高达75%以上。此外,则进一步确保了犯罪者照片为普通证件照片,而非被捕后拍摄照片。
反对任何歧视的武教授,对于有人提出将研究用于甄别罪犯或“潜在犯罪者”时更是表示强烈反对。其更希望有人从学术角度与其探讨甚至推翻其结论。但他也意识到了隐藏在背后的另一个问题“人工智能研究应如何划定价值伦理的禁区。”
来自谷歌研究员的批驳
去年11月发布的文章,如今再一次处于风口浪尖,更招致来自国外三名研究者的批驳,这无疑是武张二人未曾预料的。三人分别是,从微软跳槽到谷歌的机器学习领域著名工程师Blaise Agüeray Arcas、谷歌AI研究员Margaret Mitchell、以及普林斯顿大学神经科学教授Alexander Todorov。他们联合在新媒体网站Medium上发表了《相面术的新外衣》(Physiognomy’s New Clothes),矛头直指以武张二人的研究所代表的“科学种族主义”。
深受种族主义陷坑的西方,对于种族主义任何形式的借尸还魂都尤为注意。而武张二人的研究正好陷入这一雷区。但除了深恐“科学种族主义”借人工智能的外衣重新具有可信度外,针对于武张二人寻求的学术讨论,谷歌研究员等人在论文中对其进行了回应:
在针对于数据训练中可能出现了过拟合,计算机能够记住某些样本的正确答案。就像考试中,考题都是此前未遇到的,而不是课堂上学到的东西。此外,机器学习系统具备参数,增加参数能够记住更多的训练数据,在数量过小的同时也更容易产生过拟合。“少于2000个样本不足以训练和测试CNN(上文中的分类器)”显然成为诟病要素之一。
此外,爬虫获取的身份证图像没办法保证都是“非犯罪分子”,根据统计学,其中一部分人也可能从事犯罪活动。
而年龄选取设定在18—55岁,在实际审讯过程中法官会首先排除的就是年龄偏见。
在论文中所选择的图像显示,“非罪犯”均身着白领衬衫,而“罪犯”则没有。虽然仅是三个例子,也不知是否代表整个数据集。但深度学习技术可能会将其视为一个区分的线索。除此以外,笑容和皱眉也在“罪犯”跟“非罪犯”之间很容易进行区分。

而对整个实验最为重要的一点质疑,或许正是解答武张二人疑惑的关键:为何证伪最后却成了证实。武张二人很可能认为,输入和输出都是客观的,他们得到的结论并不具备任何主观臆断。但在三名研究者看来,武张二人陷入了客观的谬误之中。因为“犯罪类型”的脸预设了几个假定前提:
一个人的脸部外观纯粹是天生的;
“犯罪”是某一群人的天然属性;
法律制度下刑事判决定罪不受面部外观影响。
而这些假设显然存在问题。而除了谬误之外,他们的研究发展逻辑可能会是以色列创业公司Faception正在采取的步骤:用计算机视觉和机器学习技术从脸部图像识别“高智商”、“白领罪犯”、“恋童癖者”和“恐怖主义者”。 并进而将带有偏见的问题合法化。
而其暴露出的实质,正如三者举出的事例一般:如果警方本来在黑人社区的巡逻就超过白人社区,这将导致更多的黑人被捕; 系统会进一步学习到,黑人社区更可能发生逮捕,从而加强了原来的人的偏见。如果采用武张二人的结论,可能会发生的现象也同样如此,并进一步扩大其偏见。
而武教授则应对三人做出了如下回应:“三个作者忽略我们原文中的一再声明,我们没有兴趣也无社会科学的学术背景解释我们的结果,讨论其成因。更没有暗示要用于执法司法。他们硬把这些意思强加给我们。”“在价值观上我们与此文作者没有任何差别,他们歪曲我们的初衷,为了给自己找一个假想敌。”
零镜观点
如同武教授指出的那样,他们无意于在“执法司法”等领域进行争论。但批驳文章所暴露出的实质之一,恰恰正是对新时代“科学种族主义”的恐惧。恐惧AI成为新的工具,也恐惧新一轮种族主义的蔓延。
而除了恐惧之外,还应该看到的无疑是我们在文章中就曾写道的,要确保AI技术朝着有利于人类的方向进步,而不是随意受人掌控得出各种可能反人类的结论。如何确保冰冷的人工智能始终处于掌控,并合理使用,这才是论文想要探索的重点。而在文末,其无疑给我们带来了清晰的启示:
机器学习也可能被误用,而这往往是无意的。这种误用往往是源于对技术问题狭隘的偏执,包括:
缺乏对训练数据偏见来源的洞察力;
缺乏对该领域现有研究的仔细审查,特别是在机器学习领域之外;
不考虑可以产生测量相关性的各种因果关系;
不考虑机器学习系统应如何被实际使用,以及在实践中可能有什么社会影响。
或许,这才是本篇批驳文章最重要的意义。
不过,在国外研究者为此大费周章之时,也许并没有注意到武教授最新的研究进展,将深度学习识别犯罪分子,转移到了《自动推断有吸引力的女性面孔造成的社会心理学印象》(Automated Inference on Sociopsychological Impressions of Attractive Female Faces),用深度学习去鉴别“妖艳”和“清纯”女子了。












